- 조회 성능 개선을 위한 반정규화 및 인덱스 설계 - Part. 1
- 조회 성능 개선을 위한 반정규화 및 인덱스 설계 - Part. 2
이전 포스팅에 이어 이번에는 검색, 정렬에 대한 요구사항이 추가됨에 따른 쿼리의 성능 비교를 해보려고 한다.
상품 목록 조회 시 상품 좋아요 항목이 같이 조회되어야 한다.
상품 목록은 브랜드 ID, 상품명으로 검색이 가능해야 한다.
상품 목록은 최신순, 좋아요 순으로 정렬이 가능해야 한다.
이번엔 이전과 동일한 조건에서 검색 조건으로 brandId, name, brandId&name 3개의 케이스로 성능을 확인해 본다.
브랜드(brand): 100건
상품(product): 10만 건
사용자(member): 1만 건
상품 좋아요(product_like): 1000만 건
상품 좋아요 수(product_like_count): 10만 건
인덱스 미적용
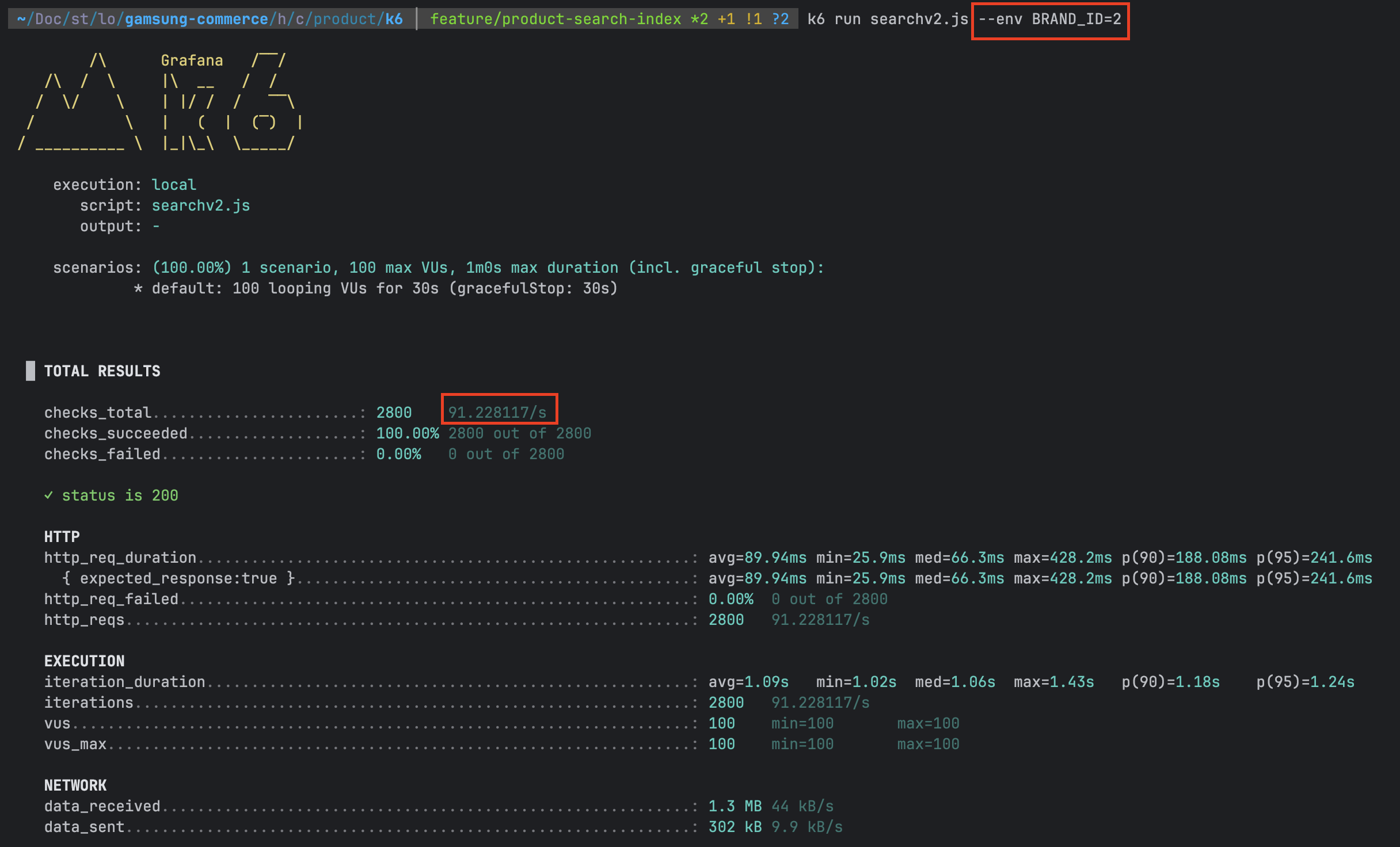


| 검색 조건 | TPS | p(90) | p(95) |
| brandId | 약 91 | 약 180ms | 약 240ms |
| name | 약 89 | 약 170ms | 약 226ms |
| brandId & name | 약 90 | 약 150ms | 약 213ms |
인덱스 적용
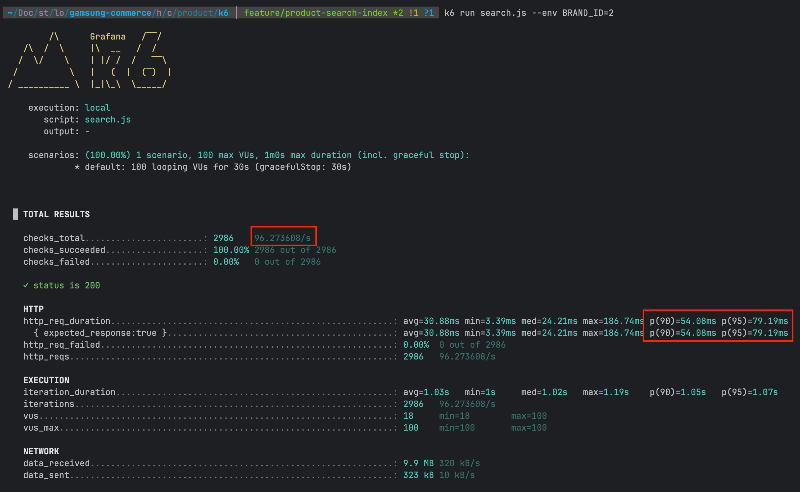

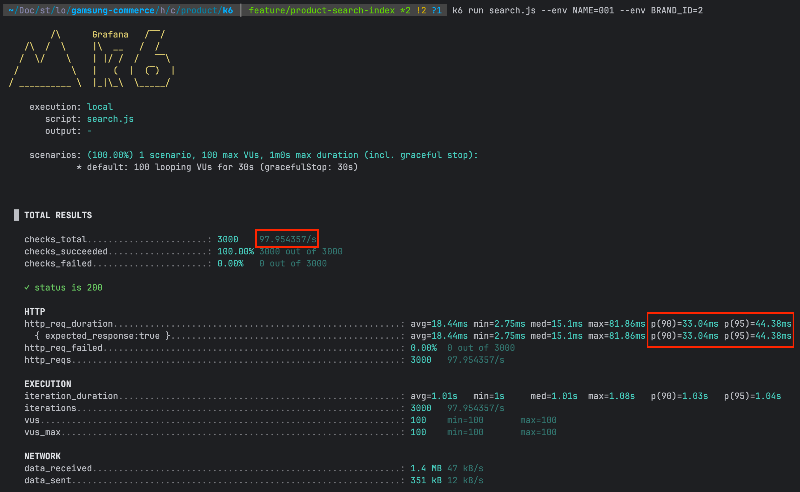
| 검색 조건 | TPS | p(90) | p(95) |
| brandId | 약 95 | 약 43ms | 약 79ms |
| name | 약 95 | 약 43ms | 약 65ms |
| brandId & name | 약 97 | 약 33ms | 약 44ms |
인덱스를 생성해도 실제 쿼리 실행 시 인덱스를 사용하지 못할 때
많이들 아시는 내용일 수 있지만 다시 한번 확인해 보면, '%상품1%'처럼 앞에 '%'가 붙으면 문자열의 시작 위치가 불확정이 되어 정렬 순서의 의미가 사라진다.
따라서 인덱스가 “처음부터 읽고 일치 여부를 검사”해야 하므로, 결국 풀스캔이 발생한다.
# name 컬럼에 대해 like 비교 시 앞뒤로 '%' 사용 시
WHERE name LIKE '%상품1%'
lower(name)과 인덱스가 참조하는 값이 원본 값인데, 쿼리 실행 시 먼저 가공을 해버리면 인덱스에 저장된 정렬 순서와 매칭할 수 없게 되어 결국 이 쿼리도 풀스캔이 발생한다.
# name 컬럼 값을 가공할 때 (좌변 값 가공)
WHERE lower(name) LIKE '상품%'
검색 조건 (인덱스 적용/미적용 쿼리 실행 계획 비교)
brandId (단일 인덱스)


name (단일 인덱스)


brandId & name (복합 인덱스)


검색 조건에 해당하는 컬럼에 인덱스를 적용하지 않게 되면 모든 행을 대상으로 where절에서 필터링을 진행하게 된다.
인덱스를 적용하게 되면 where절에서 필터링을 하는 것이 아닌 인덱스에서 이미 필터링한 후 이를 기반으로 진행하게 된다.
정렬 조건(인덱스 적용/미적용 쿼리 실행 계획 비교)
최신순 (created_at)


좋아요 순 (product_like_count)


정렬 조건의 경우 인덱스를 적용하지 않게 되면 모든 행을 대상으로 정렬을 진행하게 되는데 이때 데이터의 수가 많으면 임시 테이블을 사용하여 데이터를 정렬하게 된다.
실행 계획 Extra에서 주목해야 할 값들
- Using index : 커버링 인덱스 사용. 데이터 파일 접근 없이 인덱스만으로 결과 반환 → 좋음.
- Using where : 인덱스 사용하더라도 추가 필터링 필요.
- Using temporary : 임시 테이블 사용. 주로 GROUP BY, DISTINCT, 복잡한 정렬 시 발생 → 메모리/디스크 사용 가능.
- Using filesort : 인덱스 정렬이 아닌 별도 정렬. 대량 데이터에서 성능 저하.
- Using index condition : Index Condition Pushdown(ICP) 사용 → 성능 이점 있음.
- Using join buffer : 조인 최적화 실패로 조인 버퍼 사용. 조인 인덱스 튜닝 필요.
커버링 인덱스 (Covering Index)
커버링 인덱스(Covering Index)는 쿼리에 필요한 모든 컬럼이 인덱스 안에 포함되어 있어, 인덱스만 읽고 결과를 반환할 수 있는 인덱스를 말한다.
즉, 일반적으로 인덱스는 검색 조건에만 사용되고 나머지 컬럼 값을 가져오기 위해 테이블 접근이 필요하지만,
커버링 인덱스는 인덱스 자체가 데이터를 모두 가지고 있으므로 테이블을 조회할 필요가 없어 I/O 횟수를 줄이고 성능을 크게 향상할 수 있다.
MySQL 실행 계획의 Extra 컬럼에 Using index가 표시되면 커버링 인덱스가 적용된 것이다.
적절히 설계된 커버링 인덱스는 디스크 I/O를 크게 줄여, 조회 성능을 극적으로 향상시킬 수 있다.
SELECT p.id, p.name, p.price, p.status, b.name, plc.product_like_count, p.created_at
FROM product p
JOIN brand b ON p.brand_id = b.id
JOIN product_like_count plc ON p.id = plc.product_id
limit 0, 20
CREATE INDEX idx_product_covering
ON product (brand_id, id, name, price, status, created_at);
위와 같은 쿼리가 있다고 할 때 SELECT 대상 컬럼을 모두 인덱스에 포함해 데이터 페이지 접근 없이 인덱스만 읽도록 했다.

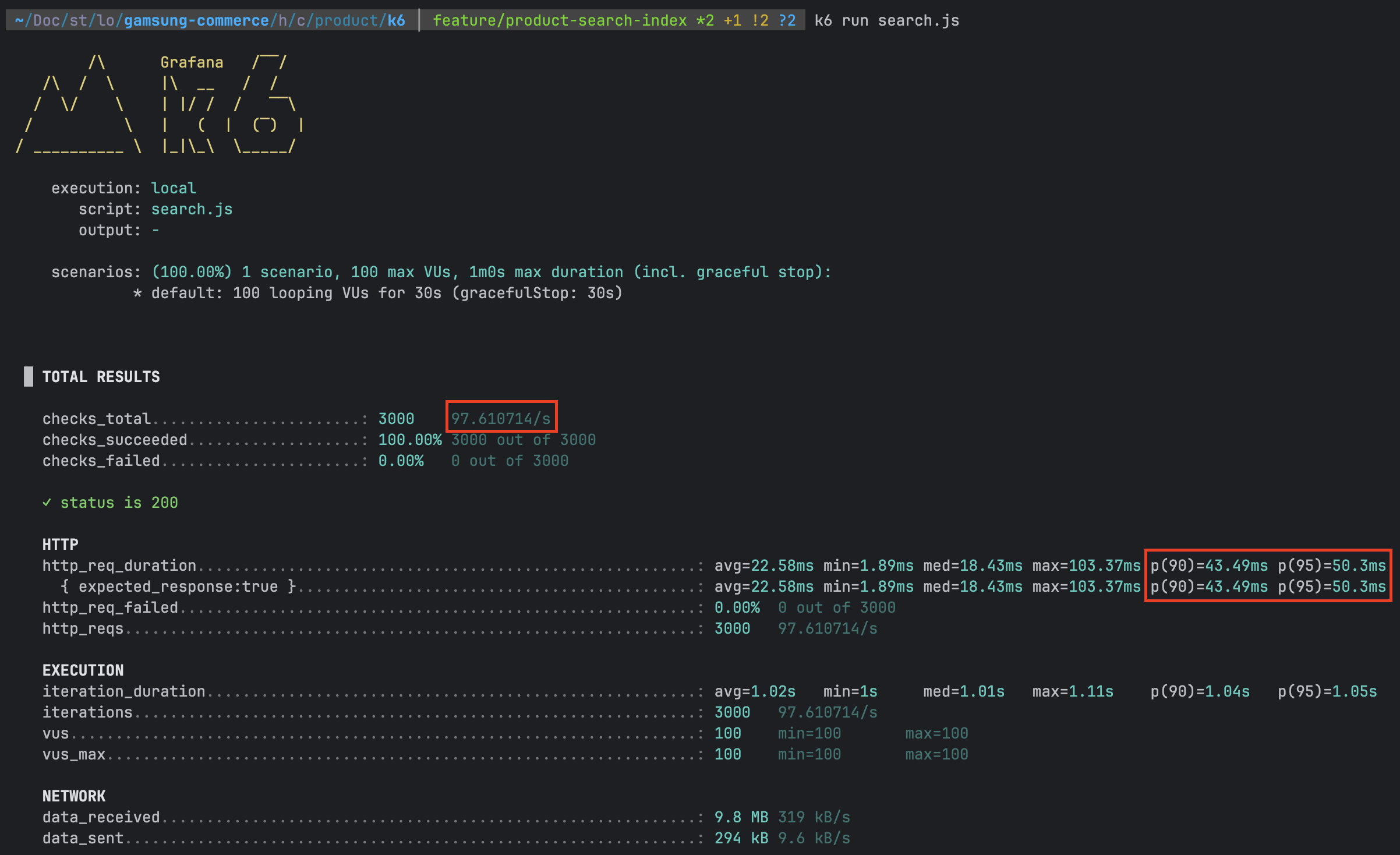
k6를 통해 다시 성능을 확인해 보면 TPS 자체는 크게 달라지지 않았지만 p(90), p(95)가 크게 향상된 것을 확인할 수 있다.
이렇게만 보면 커버링 인덱스는 무조건 좋은 거 아니야?라고 할 수도 있겠으나 다음과 같은 단점이 있기 때문에 주의해서 사용해야 한다.
컬럼이 많아질수록 인덱스 크기 증가 → 쓰기(INSERT/UPDATE/DELETE) 성능 저하 가능.
SELECT 컬럼 변경 시 인덱스 재설계 필요.
모든 테이블에 커버링 인덱스를 적용하는 것은 비효율적 → 핵심 쿼리 위주로 적용.
정리
| 케이스 | TPS | p(90) | p(95) |
| 반정규화를 적용 X 인덱스 적용 X GRUOP BY + COUNT |
약 0.19 | 약 26.12s | 약 26.19s |
| 반정규화 적용 X 인덱스 적용 O GROUP BY + COUNT |
약 6.5 | 약 15.16s | 약 16.19s |
| 반정규화 적용 O | 약 23 | 약 3.65s | 약 4.62s |
| 검색 조건 brandId 인덱스 적용 O |
약 95 | 약 43ms | 약 79ms |
| 검색 조건 name 인덱스 적용 O |
약 95 | 약 43ms | 약 65ms |
| 검색 조건 brandId & name 인덱스 적용 O |
약 97 | 약 33ms | 약 44ms |
| 커버링 인덱스 적용 O | 약 97 | 약 43.49ms | 약 50.3ms |
페이징 쿼리의 성능 저하
앞서 페이징 쿼리에 인덱스를 적용하여 조회 성능을 높였는데, 그럼에도 불구하고 페이지 offset이 증가함에 따라 페이징 쿼리는 다시 조회 성능이 저하된다.
# offset이 클 경우에는 다시 성능 저하 문제가 발생한다.
SELECT p.id, p.name, p.price, p.status, b.name, plc.product_like_count, p.created_at
FROM product p
JOIN brand b ON p.brand_id = b.id
LEFT JOIN product_like_count plc ON p.id = plc.product_id
LIMIT 700000, 20 // 너무 큰 offset
20 rows retrieved starting from 1 in 1 s 274 ms (execution: 932 ms, fetching: 342 ms)

실행 계획을 확인해 보면 인덱스를 사용하지 못하고 테이블 풀스캔이 발생한 것을 확인할 수 있다.
OFFSET은 결과 집합에서 지정된 개수만큼의 행을 건너뛴 후(읽은 후 버림), 그다음 행부터 데이터를 반환하는 방식이다.
하지만 이 과정에서 OFFSET에 해당하는 모든 행을 실제로 읽어야 하므로, 인덱스를 적용했더라도 테이블의 데이터를 풀스캔하여 성능이 저하된다.
특히 OFFSET 값이 커질수록 “읽고 버리는 데이터”의 양이 많아져, 페이지가 뒤로 갈수록 쿼리 성능은 급격히 떨어진다.
이 문제를 해결하기 위해 No OFFSET 방식을 사용할 수 있다.
No OFFSET 방식은 OFFSET을 사용하지 않고, 이전에 조회한 목록의 마지막 ID를 기준으로 다음 페이지를 조회하는 방식으로, 불필요한 데이터 스캔을 줄이고 인덱스를 효율적으로 활용할 수 있다.
SELECT p.id, p.name, p.price, p.status, b.name, plc.product_like_count, p.created_at
FROM product p
JOIN brand b on p.brand_id = b.id
LEFT JOIN product_like_count plc on p.id = plc.product_id
WHERE p.id > 700000 // offset 대신 pk 전달
LIMIT 20
20 rows retrieved starting from 1 in 401 ms (execution: 6 ms, fetching: 395 ms)

실행 계획을 확인해 보면 No Offset 방식은 인덱스를 사용하는 것을 확인할 수 있다.
하지만 No OFFSET 방식을 사용할 때는 검색 조건과 정렬 조건, 데이터의 변경을 반드시 고려해야 한다.
No OFFSET은 정렬된 인덱스 값을 기준으로 순차적으로 데이터를 조회하는 방식인데, 여기에 검색 조건이나 정렬 조건이 추가되면 인덱스의 정렬 순서가 달라질 수 있다.
이 경우, 이전 페이지의 마지막 ID를 기준으로 다음 페이지를 조회하면 데이터 순서가 어긋나거나 일부 데이터가 누락·중복되는 문제가 발생할 수 있다.
또 데이터가 변경되었을 경우 다음 페이지 요청 시 데이터가 중복되거나 누락되는 문제가 발생할 수 있다.

TODO
- k6로 진행한 성능 테스트에 대해 모니터링 시스템을 이용하여 그래프로 시각화
'Database > MySql' 카테고리의 다른 글
| 조회 성능 개선을 위한 반정규화 및 인덱스 설계 - Part. 1 (4) | 2025.08.18 |
|---|---|
| 좋아요 수 관리는 단순하지 않다. (2) | 2025.07.24 |


댓글