- 조회 성능 개선을 위한 반정규화 및 인덱스 설계 - Part. 1
- 조회 성능 개선을 위한 반정규화 및 인덱스 설계 - Part. 2
이번 포스팅에서는 조회 성능을 개선하기 위한 방법들인 반정규화와 인덱스에 대해 알아본다.
"조회"란 무엇인가?
1. "조회"라는 건 저장된 정보를 사용자가 요청하여 확인하는 것을 의미한다."정보"는 어디에 저장되는가?
1. 정보는 보통 데이터베이스(DB)에 저장된다.
2. DB는 내부적으로 메모리(Buffer Pool)와 디스크에 정보를 보관한다.
3. 사용자가 정보를 조회하면, DB는 먼저 메모리(Buffer Pool)에서 데이터를 찾는다.
4. 메모리에 없으면 디스크에서 읽어오며, 이때 Disk I/O가 발생한다.
5. 디스크 접근은 메모리 접근보다 훨씬 느리기 때문에, Disk I/O를 줄이는 것이 성능 개선의 핵심이다."조회 성능을 개선한다"는 것은 무슨 뜻일까?
1. 조회 성능을 개선한다는 것은 현재 조회 속도가 만족스럽지 않다(=느리다)는 뜻이다.
2. 조회 속도가 느리다는 것은 사용자가 요청한 결과를 반환하는 데 시간이 오래 걸린다는 의미다.
3. 시간이 오래 걸리는 이유는 여러 가지가 있을 수 있다.
(예: 불필요하게 많은 데이터 스캔, 인덱스 미활용, 복잡한 조인, 네트워크 지연 등)
4. 그중 대표적인 원인이 Disk I/O가 많아지는 상황이다.
5. Disk I/O가 많다는 것은 필요한 데이터 외에 불필요한 데이터까지 읽어들이거나, 인덱스 없이 전체 검색을 한다는 것을 의미한다.
6. 결국 조회 성능을 개선한다는 것은 읽어야 하는 행(Row) 수를 최소화 하여 Disk I/O를 줄이는 것이다.
이제 조회 성능을 개선하기 위한 방법들인 반정규화, 인덱스에 대해서 알아본다.
"반정규화"란 무엇인가?
1. 정규화(Normalization) 는 데이터 중복을 제거하고, 테이블을 세분화하여 데이터 무결성을 높이는 설계 방법입니다.
2. 반정규화(Denormalization) 는 이와 반대로 성능 향상을 위해 데이터 중복을 허용하거나, 테이블 구조를 단순화하는 설계 방식입니다.
3. 쉽게 말해, "데이터 무결성"은 일부 포기하는 대신 "조회 속도"를 높이는 방식입니다.왜 반정규화를 사용하는가?
1. 정규화된 구조는 데이터 일관성은 높지만, 조회 시 여러 테이블을 조인(Join)해야 하므로
Disk I/O가 늘어나고 응답 속도가 느려질 수 있습니다.
2. 반정규화는 조인 횟수를 줄여 한 번의 조회로 필요한 데이터를 가져올 수 있게 만들어,
읽어야 하는 행(Row) 수를 줄이고 Disk I/O를 최소화합니다.
반정규화의 장/단점
| 장점 | 단점 |
| 조인(join) 연산 감소 -> 조회 속도 향상 | 데이터 중복 증가 -> 저장 공간 낭비 |
| 조회에서 필요한 데이터를 한 번에 반환 가능 | 데이터 변경 시 여러 테이블을 동시에 수정해야 하는 부담 증가 |
| 복잡한 SQL을 단순화 | 동기화 이슈 발생 가능 |
반정규화는 "데이터를 덜 읽기 위해, 조금 더 써서 저장하는" 전략이다.
조회 성능은 빨라지지만, 쓰기와 관리 비용이 올라갈 수 있으므로 신중히 적용해야 한다.
인덱스란 무엇인가?
인덱스를 찾아보면 인덱스는 '데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료 구조를 뜻한다.'라고 되어 있다.
조금 더 이해하기 쉽게 설명하자면 인덱스는 '데이터를 빨리 찾기 위해 인덱스가 되는 컬럼을 기준으로 미리 정렬해 놓은 표'라고도 할 수 있다.
인덱스 사용 시 주의점
인덱스 관리로 인한 쓰기 트레이드 오프
하지만 인덱스는 인덱스로 지정된 컬럼의 정렬된 정보를 별도의 공간에 저장해야 하기 때문에 추가적인 저장 공간을 차지하며, 이는 해당 테이블에 대해 쓰기 작업이 발생할 때마다 인덱스 정보를 갱신해야 하는 단점이 생긴다.
따라서 필요한 컬럼에 대해서만 인덱스를 생성해야 하며 불필요한 컬럼까지 인덱스로 생성하게 될 경우 쓰기 성능 저하가 발생할 수 있다.
카디널리티(Cardinality)가 높은 컬럼에 사용
카디널리티는 특정 테이블에 있는 데이터 중 특정 컬럼 값의 유니크한 정도를 의미한다.
| 카디널리티가 높다 | 중복이 적다 | ex: 주민번호, 이메일... |
| 카디널리티가 낮다 | 중복이 많다 | ex: 성별, 이름... |
카디널리티를 확인할 때는 데이터의 개수를 함께 고려해야 한다.
카디널리티는 절대적인 값이 아니라, 해당 테이블의 데이터 값에 따라 상대적으로 판단해야 한다.
예를 들어, 주민번호, 이메일등은 카디널리티가 높다고 표현했는데 만약 데이터가 아래와 같이 1건만 있다고 하면 어떨까?
| id | gender | |
| 1 | shyoon991@gmail.com | M |
이 경우 이메일과 성별 모두 카디널리티가 1로 동일하다.
즉, 카디널리티를 판단할 때는 항상 실제 테이블의 데이터 개수를 확인하고 계산하는 것이 중요하다.
복합 인덱스 사용 시 인덱스 순서 주의
하나의 인덱스에 여러 컬럼을 포함하는 복합 인덱스를 만들 수 있는데, 이때 컬럼의 순서와 조건 비교 방식(=, >, <, between, like)을 고려해야 한다.
-- product에 대해서 (brand_id, product_name)로 복합 인덱스를 구성했을 때,
-- 인덱스 효율적으로 사용 (brand_id → product_name 순서 모두 사용)
SELECT * FROM product
WHERE brand_id = 10
AND product_name LIKE 'A%';
-- brand_id 조건 없음 → 인덱스의 첫 번째 정렬 기준이 깨짐
SELECT * FROM product
WHERE product_name LIKE 'A%';
-- product에 대해서 (brand_id, price)로 복합 인덱스를 구성했을 때,
-- brand_id 범위 검색 → price는 인덱스 활용 어려움
SELECT * FROM product
WHERE brand_id > 5
AND price < 10000;
인덱스 추가
SQL에서는 인덱스 생성 문법을 사용하여 인덱스를 추가할 수 있고, JPA의 기능을 사용해서도 인덱스를 추가할 수 있다.
# MySQL
CREATE INDEX 인덱스명 ON 테이블명 (컬럼명1, 컬럼명2, ...)
# JPA
@Table(name = "product",
indexes = {
@Index(
name = "idx_product_brand_id",
columnList = "brandId"
)
}
)
@Entity
class Product {
// ...
}반정규화를 적용하지 않은 상품 목록 조회 성능 확인
다음과 같은 요구사항이 있다고 가정해 보자.
상품 목록 조회 시 상품 좋아요 항목이 같이 조회되어야 한다.

상품, 상품 좋아요가 위와 같이 설계되었다고 하면 다음과 같이 상품 목록을 조회해야 한다.
# 상품 목록 조회
SELECT p.id, p,name, p.status, p.desription, COUNT(pl.id) AS product_like_count
FROM product p
LEFT OUTER JOIN product_like pl
ON p.id = pl.product_id
GROUP BY p.id
이 방식은 product_like 테이블에서 각 상품(product)의 좋아요 수를 COUNT(pl.id)로 집계하여 조회한다.
그러나 COUNT 집계 특성상, product_like 테이블의 데이터가 많아질수록 조회해야 하는 행(Row)의 수가 증가하고, 이에 따라 조회 성능이 크게 저하될 수 있다.
사전 데이터 설정
* 성능 비교를 위해 아래와 같이 사전 데이터를 설정해 두었다.
브랜드(brand): 100건
상품(product): 10만 건
사용자(member): 1만 건
상품 좋아요(product_like): 1000만 건
상품 좋아요 수(product_like_count): 10만 건
아래는 k6를 이용한 성능 테스트 결과와 함께, 쿼리의 실행 계획 및 실행 시간을 측정한 내용이다.

# 실행 계획 확인
EXPLAIN (SELECT p.id, p.name, p.price, p.status, b.name, COUNT(pl.id), p.created_at
FROM product p
JOIN brand b ON b.id = p.brand_id
LEFT JOIN product_like pl ON pl.product_id = p.id
GROUP BY p.id
LIMIT 0, 20);
# 실행 시간 확인
(SELECT p.id, p.name, p.price, p.status, b.name, COUNT(pl.id), p.created_at
FROM product p
JOIN brand b ON b.id = p.brand_id
LEFT JOIN product_like pl ON pl.product_id = p.id
GROUP BY p.id
LIMIT 0, 20)
20 rows retrieved starting from 1 in 16 s 929 ms (execution: 16 s 550 ms, fetching: 379 ms)

k6를 통한 부하 테스트 결과, 0.19 TPS라는 매우 저조한 성능이 측정되었다.
(일반적인 설정 값으로는 지속적으로 timeout이 발생했으며, 강제로 설정 값을 조정한 뒤에야 0.19라는 수치를 겨우 얻을 수 있었다.)
쿼리 실행 계획을 살펴보면
type=index, extra=Using where + Using index + Using join buffer로 표시되었다.
이는 곧,
인덱스를 전부 스캔하면서(=Index Full Scan), 조건으로 필요한 데이터만 거르고(Using where),
테이블 데이터 페이지로 내려가지 않고 인덱스 안에서만 데이터를 읽으며(Using index),
조인에서는 인덱스가 제대로 활용되지 않아 조인 버퍼(해시 조인)를 사용했다
라는 의미다.
실제로 20건만 조회하는 쿼리임에도 실행 시간이 약 16초나 소요되었으며,
이는 데이터 건수가 많아질수록 성능 저하가 기하급수적으로 심각해질 수 있음을 보여준다.
데이터가 적을 때는 문제가 잘 드러나지 않지만, 데이터가 일정 규모 이상으로 증가하면 비로소 병목이 발생한다.
이는 과거 인스타그램의 저스틴 비버 사건에서도 확인된 바 있다.
다음으로 소개할 반정규화를 적용하면 이를 개선할 수 있지만, 만약 실무에서 지금 당장 반정규화를 적용할 수 없는 상황이라면 product_like 테이블에 인덱스를 추가함으로써 조금이나마 성능을 개선해 볼 수 있다.
product_like 테이블에 인덱스 추가하기
여기서도 주의해야 할 부분은 인덱스를 어떻게 추가하느냐에 따라서 인덱스를 사용하거나 사용하지 않는다.
아래는 인덱스 생성 케이스에 따른 인덱스 사용/미사용 여부다.
| 인덱스 케이스 | 사용 여부 |
| CREATE INDEX idx_product_user ON product_like (product_id, user_id) | 사용 |
| CREATE INDEX idx_product ON product_like (product_id) | 사용 |
| CREATE INDEX idx_user_product ON product_like (user_id, product_id) | 미사용 |
현재 쿼리의 중요한 부분은 product_id이기 때문에 product_id에 대해 인덱스가 있다면 쿼리 실행 시 인덱스를 사용하여 이전보다 더 빠르게 조회할 수 있다.
주의 깊게 봐야 할 부분은 인덱스를 (user_id, product_id) 순서로 생성했을 경우에는 인덱스를 사용하지 못한다는 점이다.
이렇게 여러 컬럼으로 구성된 복합 인덱스는 선행 컬럼의
아래는 k6를 이용한 성능 테스트 결과와 함께, 쿼리의 실행 계획 및 실행 시간을 측정한 내용이다.

# 실행 계획 확인
EXPLAIN (SELECT p.id, p.name, p.price, p.status, b.name, COUNT(pl.id), p.created_at
FROM product p
JOIN brand b ON b.id = p.brand_id
LEFT JOIN product_like pl ON pl.product_id = p.id
GROUP BY p.id
LIMIT 0, 20);
# 실행 시간 확인
(SELECT p.id, p.name, p.price, p.status, b.name, COUNT(pl.id), p.created_at
FROM product p
JOIN brand b ON b.id = p.brand_id
LEFT JOIN product_like pl ON pl.product_id = p.id
GROUP BY p.id
LIMIT 0, 20)
20 rows retrieved starting from 1 in 352 ms (execution: 8 ms, fetching: 344 ms)

k6를 통한 부하 테스트 결과, 약 6.5 TPS로 인덱스 미적용 CONT 집계 쿼리에 비해 약 34배 성능이 개선된 것을
확인할 수 있다.
쿼리 실행 계획은 product_id를 기반으로 생성한 인덱스를 사용하여 조회 행수를 크게 줄인 것 또한 확인할 수 있다.
쿼리 실행 시간은 약 400ms로 인덱스 미적용 COUNT 집계 쿼리에 비해 약 36배 빠른 속도인 것을 확인할 수 있다.반정규화를 적용한 상품 목록 조회 성능 개선
앞서 살펴본 문제를 해결하기 위해 반정규화를 적용해 조회 성능을 개선할 수 있다.
상품 좋아요 수 집계를 최적화하기 위해, product_like_count 테이블을 별도로 생성하여 반정규화를 적용한다.

이제 상품 좋아요 정보를 조회할 때, product_like 테이블에서 COUNT 집계를 수행하지 않고, product_like_count 테이블에서 productLikeCount 값을 직접 읽어올 수 있다.
아래는 k6를 이용한 성능 테스트 결과와 함께, 쿼리의 실행 계획 및 실행 시간을 측정한 내용이다.
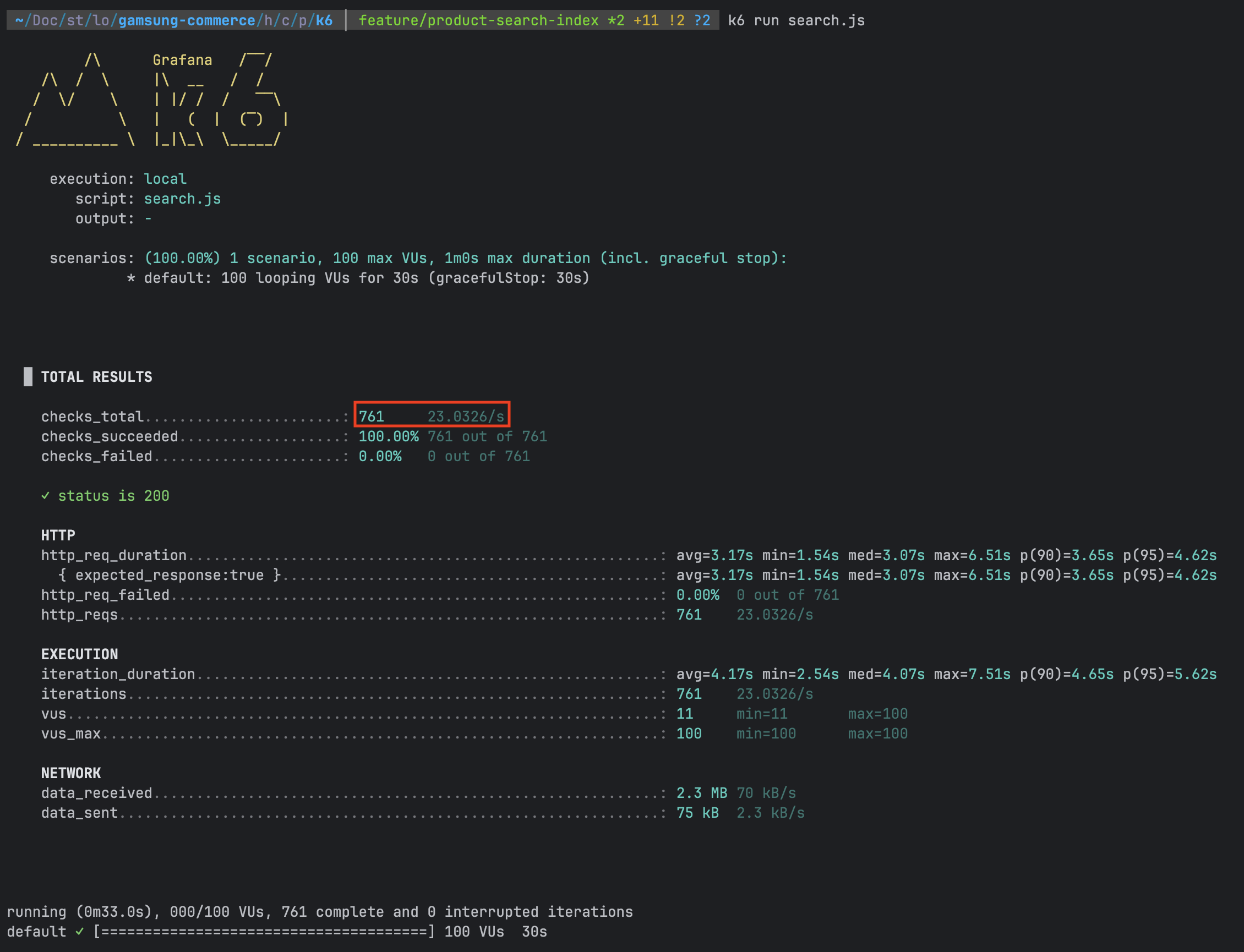
# 실행 계획 확인
EXPLAIN (SELECT p.id, p.name, p.price, p.status, b.name, plc.product_like_count,
p.created_at
FROM product p
JOIN brand b ON p.brand_id = b.id
LEFT JOIN product_like_count plc ON p.id = plc.product_id
LIMIT 0, 20);
# 실행 시간 확인
(SELECT p.id, p.name, p.price, p.status, b.name, plc.product_like_count, p.created_at
FROM product p
JOIN brand b ON p.brand_id = b.id
LEFT JOIN product_like_count plc ON p.id = plc.product_id
LIMIT 0, 20)
20 rows retrieved starting from 1 in 445 ms (execution: 10 ms, fetching: 435 ms)

k6를 통한 부하 테스트 결과, 23 TPS로 CONT 집계 쿼리에 비해 약 121배나 성능이 개선된 것을 확인할 수 있다.
쿼리 실행 계획은 PK를 기반으로 조회 행수를 크게 줄인 것 또한 확인할 수 있다.
쿼리 실행 시간은 약 445ms로 COUNT 집계 쿼리에 비해 약 36배 빠른 속도인 것을 확인할 수 있다.
위와 같이 반정규화를 적용해 상품 목록 조회 성능을 개선했다.
그러나 새로운 요구사항이 추가되었다.
상품 목록 조회 시 상품 좋아요 항목이 같이 조회되어야 한다.
상품 목록은 브랜드 ID, 상품명으로 검색이 가능해야 한다.
상품 목록은 최신순, 좋아요 순으로 정렬이 가능해야 한다.
위처럼 검색 및 정렬 조건이 추가되면, 다시 한번 조회 성능이 크게 저하될 수 있다.
이를 해결하기 위해서는 적절한 인덱스 설계가 필요하다.
정리
| 케이스 | TPS | p(90) | p(95) |
| 반정규화를 적용 X 인덱스 적용 X GRUOP BY + COUNT |
약 0.19 | 약 26.12s | 약 26.19s |
| 반정규화 적용 X 인덱스 적용 O GROUP BY + COUNT |
약 6.5 | 약 15.16s | 약 16.19s |
| 반정규화 적용 O 인덱스 적용 X |
약 23 | 약 3.65s | 약 4.62s |
인덱스 설계에 대한 내용은 2편에서 이어서 진행해 본다.
'Database > MySql' 카테고리의 다른 글
| 조회 성능 개선을 위한 반정규화 및 인덱스 설계 - Part. 2 (4) | 2025.08.18 |
|---|---|
| 좋아요 수 관리는 단순하지 않다. (2) | 2025.07.24 |


댓글