이번 주 과제를 통해 카프카(Kafka)를 학습하면서, 단순히 메시지를 주고받는 MQ(Message Queue) 정도로 생각했던 인식이 완전히 바뀌었다.
카프카에서 소개하는 분산 이벤트 스트리밍 플랫폼이 어떤 느낌인지 대략적으로라도 느낄 수 있었다.
카프카와 MQ 비교
처음 카프카를 접했을 때는 RabbitMQ, ActiveMQ처럼 “메시지를 보내고 받는 도구” 정도로만 생각했다.
하지만 이번 과제를 진행하면서 카프카의 본질적인 차이점을 알게 되었다.
| 구분 | MQ | Kafka |
| 메시지 저장 방식 | 메시지를 소비하면 큐에서 삭제 | 토픽에 로그 형태로 영속 저장 |
| 데이터 재처리 | 기본적으로 어려움 | 오프셋을 기반으로 자유롭게 재처리 가능 |
| 처리 모델 | 단순 메시지 전달 | 스트리밍 플랫폼 + 이벤트 로그 |
| 확장성 | 제한적 | 분산 시스템 기반, 컨슈머 그룹으로 병렬 처리 가능 |
카프카를 왜 써야 할까?
카프카의 필요성을 이번 과제를 하면서 직접 체감했다.
특히 실시간 이벤트 기반 시스템을 설계할 때 카프카가 가진 강점들이 돋보였다.
안정적인 이벤트 처리
오프셋(Offset) 개념 덕분에 컨슈머가 어디까지 읽었는지 명확히 관리 가능
장애 상황에서 재처리가 용이하여 데이터 손실 가능성을 최소화
실시간 스트리밍 처리
사용자 행동, 주문 이벤트, 결제 상태 변경 등 실시간 데이터를 빠르게 흘려보내고 소비 가능
별도의 API 호출 없이 토픽을 통해 필요한 서비스에서 즉시 반응할 수 있음
서비스 간 결합도 최소화
A 서비스가 B, C, D를 직접 호출하지 않아도 됨
A에서 이벤트를 발행하면 필요한 서비스가 구독(Subscribe)하여 처리
덕분에 서비스 간 의존성이 크게 줄어들고 확장성이 향상됨
데이터 파이프라인 통합
서비스 간 메시징뿐만 아니라 데이터 웨어하우스, 알림 시스템, 로그 분석 등 다양한 목적에 재활용 가능
이벤트 기반으로의 전환
이번 학습에서 가장 큰 변화는 시스템을 바라보는 시각이었다.
그동안은 절차지향적 사고에 익숙했다.
“A → B → C → D”로 이어지는 호출 체인
흐름 제어가 한곳에 집중되다 보니, 서비스 간 결합도가 높아지고 유지보수가 어려워짐
하지만 카프카 기반으로 설계하면서 사고방식이 바뀌었다.
“A에서 이벤트를 발행하면, 필요한 서비스가 알아서 반응한다”
이벤트를 중심으로 각 서비스가 독립적으로 동작하며 상호작용
서비스 간 결합도를 낮추면서도 실시간성은 확보하는 구조를 경험
즉, "무엇을 할지"보다 "어떤 이벤트가 발생했는지"에 초점을 맞추는 방식으로 사고가 전환되었다.
그리고 직접 이벤트 흐름을 시각화해 보면서,, 한 번의 이벤트가 여러 서비스로 흘러가 서로 다른 작업을 병렬로 처리하는 과정을 직관적으로 정리해 볼 수 있었다.
상품 조회 이벤트 흐름
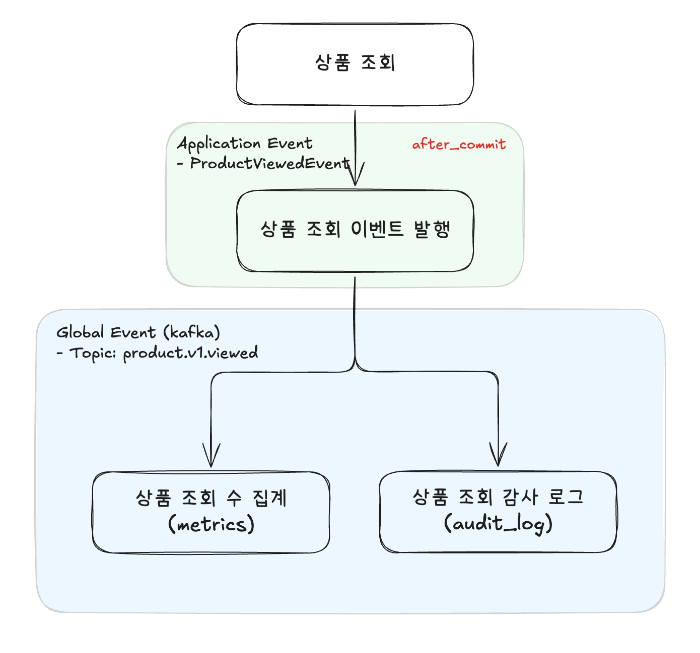
상품 변경 이벤트 흐름

상품 좋아요

주문/결제

정리
이번 주는 카프카를 단순한 메시지 큐가 아니라 실시간 데이터 스트리밍 플랫폼으로 바라보게 된 주였다.
특히 과제를 통해 토픽 설계 → 이벤트 발행 → 컨슈머 그룹 처리 → 오프셋 기반 재처리까지 직접 경험하면서 이벤트 기반 아키텍처의 장점을 몸소 느낄 수 있었다.
무엇보다, 점점 절차지향적 사고에서 벗어나 이벤트 중심으로 시스템을 설계하는 시각을 갖추고 있다는 게 이번 주 가장 핵심이었던 것 같다.
'Loopers' 카테고리의 다른 글
| Loop:Pak - 10주간의 회고 (0) | 2025.09.19 |
|---|---|
| WIL - 9주차 회고 (1) | 2025.09.12 |
| WIL - 7주차 회고 (1) | 2025.08.29 |
| WIL - 6주차 회고 (1) | 2025.08.24 |
| WIL - 5주차 회고 (2) | 2025.08.17 |
댓글